Data Analysis Assignment: Stock Return & Portfolio Analysis
Question
Task
Data Analysis Assignment Requirement: Please finish the tasks according to the requirements. All the tasks need to be finished by using R. Please present your results in the word file, copy all your R code in the end of this word file.
Answer
Data Analysis Assignment Task 1: Stock Return and Portfolio Analysis
In the file named as “Stock.csv”, you have been provided with the daily prices of three stocks from 2012 to 2018.
a. Plot and present the stock prices in time series with appropriate labels.
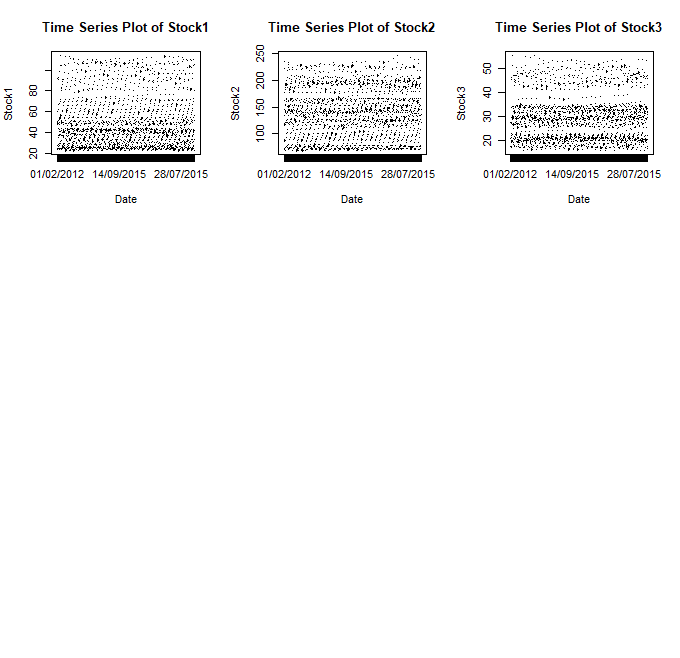
b. Calculate the log returns of all the three stocks and express them in percentages.
Pls report the descriptive statistics of log returns of three stocks in Table 1. Pls change the names in Table 1 to the stock names in your file.
Table 1: Summary Statistics
|
Variable |
MSFT |
MMM |
INTC |
|
Min |
-0.1210331 |
-0-0707713 |
-0-0954321 |
|
Max |
0.0994128 |
0.0574467 |
0.1003147 |
|
Mean |
0.0008531 |
0.0005652 |
0.0004914 |
|
Median |
0.0004509 |
0.0001858 |
0.0006775 |
|
SD |
0.01452656 |
0.01043945 |
0.01489527 |
|
Skewness |
-0.08481595 |
-0.6662234 |
-0.05525918 |
|
Kurtosis |
11.24066 |
8.315543 |
8.115963 |
|
N |
1758 |
1758 |
1758 |
c. Pls report the correlation matrix of log returns of three stocks in Table 1. Pls change the names in Table 1 to the stock names in your file.
Table 2: Correlation Matrix
|
Variable |
MSFT |
MMM |
INTC |
|
MSFT |
1.0000000 |
0.4738475 |
0.5441834 |
|
MMM |
0.4738475 |
1.0000000 |
0.4900549 |
|
INTC |
0.5441834 |
0.4900549 |
1.0000000 |
MSFT and INTC stocks highly correlated among other stock variables whereas MSFT and MMM has weak correlation.
d. There is a file named as “FF3factors.csv” in your folder. Merge your stock data with the Fama French three factors data, which are all in percentages. Pls create a new variable Stock.Rf for all the three stocks, which equals to the difference between log return of each stock and RF (available in the FF3factors.csv), and run a regression of :
Stock.Rf=?+?Mkt.Rf+u.
Report the regression results for all the three stocks in tables (you can use only one table to summarize all the results or three separate tables).
For Stock 1: Stock.Rf=-0.0239145+0.0003671Mkt.Rf+u
For Stock 2: Stock.Rf=-0.0242046+0.0003117Mkt.Rf+u
For Stock 3: Stock.Rf=-0.0242776+0.0003581Mkt.Rf+u
e. Pls run regressions of :
Stock.Rf=?+1Mkt.Rf+2SMB+3HML+u.
Report the regression results for all the three stocks in tables (you can use only one table to summarize all the results or three separate tables).
For Stock 1:
Stock.Rf=-0.0239123+0.0004275Mkt.Rf+0.0002940SMB-0.0003500HML+u
For Stock 2:
Stock.Rf=-0.0242031+0.0004039Mkt.Rf+0.0005355SMB-0.0004452HML+u
For Stock 3:
Stock.Rf=-0.0242708+0.0004460Mkt.Rf+0.002439SMB-0.0006986HML+u
f. Pls make your comments by comparing the results in d and e.
The multiple regression coefficients have larger coefficient values shows that a unit change in a new variable may change the dependent variables more than a linear regression coefficient.
g. If an investor would like to form a portfolio with a targeted expected return of 0.05% and achieve the minimized standard deviation by investing in these three stocks in the “Stock.csv” file. If the daily riskfree rate is 0.02%, what is the Sharpe ratio of this optimal portfolio, given there is no short sale constraint? [hint: can use the library of “quadprog”] [pls provide your R code used to form the optimal portfolio in the end of the word file].
Sharpe Ratio for Stock 1 = 0.00121663
Sharpe Ratio for Stock 2 = 0.0006628876
Sharpe Ratio for Stock 3 = 0.003161835
h. If an investor would like to form a portfolio with a targeted expected return of 0.05% and achieve the minimized standard deviation by investing in these three stocks. If the daily risk free rate is 0.02%, what is the Sharpe ratio of this optimal portfolio, given there is short sale constraint (i.e., you cannot short sell the stocks)? [hint: can use the library of “quadprog”]
Zk=C0k+C1kRf
C0kand C1k are the constants where k is asset value. We can determine Zk can be determine as the function of Rf. Each stock investment can be determined from at various pointsRf.
i. By comparing your answer in g) and h), is there any difference in their Sharpe ratios? Why that’s the case?
When sharp ratio is greater it shows the best performance, if it has negative sharp ratios it means risk free rate is greater than the portfolio risk free rate.
j. Given there is no short sale constraint, pls draw an efficient frontier that satisfies the following conditions: 1. The range of the mean return of the portfolio is from 0.75*min of the mean return of three stocks to 1.25*max of the mean return of three stocks; 2. Pls create 500 optimal portfolios in this range; 3 Then pls plot all the risk-return combination of the 500 optimal portfolios (i.e., the efficient frontier). [Pls provide your R code in the end of word file]
Task 2: Stock Market Reaction to FOMC Announcement
US monetary policy can be measured by changes in the Federal funds rate, which are announced by the Federal Open Market Committee (FOMC) meetings. Given the importance of monetary policy to the whole economy, investors pay special attention to the FOMC announcements. In the attached dataset (“Event Study.csv”), we have collected data on FOMC announcements from 1989 to 2007 and the aggregate stock market reactions to it.
Here is a list of variables:
- Date: FOMC announcement date
- Return: S&P 500 index return on the announcement date (in percentage)
- Total change: change of Federal fund rate (in bps)
- Expected: investors’ expected change of Federal fund rate, which is estimated based on the futures contracts written on the Federal fund rate (in bps)
- Surprise: the difference between Total change and Expected, which measures the change that is out of expectation of investors (in bps)
- Scheduled: equals to 1 if the FOMC is scheduled, and 0 if not.
a) Run three regressions and report the estimation results according.
[Note: please report the coefficient and t-statistics; indicate significance with difference levels, and the adjusted R-squared of the regression.] [pls provide your R code in the end of word file]
In the first regression, Y is Return, X is Total change;
In the second regression, Y is Return, X is Expected;
In the third regression, Y is Return, X is Surprise.
Required R code:
data1 <- read.csv("C:\\Users\\Ahmad\\Downloads\\Event Study.csv", header= TRUE)
y <- data1$Return
x1 <- data1$total.change
x2 <- data1$surprise
x3 <- data1$expected
x4 <- data1$Scheduled
fit1 <- lm(y~x1)
summary(fit1)
fit2 <- lm(y~x3)
summary(fit2)
fit3 <- lm(y~x2)
summary(fit3)
b) Comparing the three regression results, which X variable explains Y the best? Why that is the case? [Note: you may link it with market efficiency and event study]
Variable surprise best explains the regression results in all three regression lines as this variable has high R-sq (coefficient of determination).
c) Create a variable which equals to Scheduled*Surprise, and then run a regression in which Y is Return, the first X variable is Surprise, and the second X variable is Scheduled*Surprise. Report the regression results. [pls provide your R code]
Required R code:
data1 <- read.csv("C:\\Users\\Ahmad\\Downloads\\Event Study.csv", header= TRUE)
y <- data1$Return
x1 <- data1$total.change
x2 <- data1$surprise
x3 <- data1$expected
x4 <- data1$Scheduled
z <- x4*x3
fit4 <- lm(y~z)
summary(fit4)
d) Based on the results, is the effect of Surprise on Return dependent on whether the FOMC meeting is scheduled or not? Please explain.
Based on results (coefficient and pvalue), we can conclude that meeting is not scheduled.
R code:
Task 1
#log returns for Stock1
log_returns1 <- diff(log(Stock1), lag=1)
#log_returns in percentages
p <- c()
for(i in log_returns1){
p <- (log_returns1[i]/sum(log_returns1))*100
print(p)
}
summary(log_returns1)
N <- length(log_returns1)
k <- mean(log_returns1)
StandardDeviation<- sqrt(var(log_returns1))
m1=sum(log_returns1 - k)/N
m2=sum((log_returns1 - k)^2)/N
m3=sum((log_returns1 - k)^3)/N
m4=sum((log_returns1 - k)^4)/N
Sk<- m3/StandardDeviation^3;Sk
Kurtosis <- m4/(m2)^2;Kurtosis
#log returns for Stock2
log_returns2 <- diff(log(Stock2), lag=1)
#log_returns in percentages
p <- c()
for(i in log_returns2){
p <- (log_returns2[i]/sum(log_returns2))*100
print(p)
}
summary(log_returns2)
N <- length(log_returns2)
k <- mean(log_returns2)
StandardDeviation<- sqrt(var(log_returns2))
m1=sum(log_returns2 - k)/N
m2=sum((log_returns2 - k)^2)/N
m3=sum((log_returns2 - k)^3)/N
m4=sum((log_returns2 - k)^4)/N
Sk<- m3/StandardDeviation^3;Sk
Kurtosis <- m4/(m2)^2;Kurtosis
#log returns for Stock3
log_returns3 <- diff(log(Stock3), lag=1)
#log_returns in percentages
p <- c()
for(i in log_returns3){
p <- (log_returns3[i]/sum(log_returns3))*100
print(p)
}
summary(log_returns3)
N <- length(log_returns3)
k <- mean(log_returns3)
StandardDeviation<- sqrt(var(log_returns3))
m1=sum(log_returns3 - k)/N
m2=sum((log_returns3 - k)^2)/N
m3=sum((log_returns3 - k)^3)/N
m4=sum((log_returns3 - k)^4)/N
Sk<- m3/StandardDeviation^3;Sk
Kurtosis <- m4/(m2)^2;Kurtosis
#Correlation Matrix of 3 Stocks
y <- data.frame(log_returns1,log_returns2,log_returns3)
cor(y)
RCode:
#library(readxl)
data <- read.csv("C:\\Users\\Ahmad\\Downloads\\Stock.csv", header= TRUE)
Stock1 <- data$MSFT
Stock2 <- data$MMM
Stock3 <- data$INTC
Date <- data$Date
plot(Date, Stock1,xlab = "Date", ylab = "Stock1", main = "Time Series Plot of Stock1")
plot(Date, Stock2,Xlab = "Date", ylab = "Stock2", main = "Time Series Plot of Stock2")
plot(Date, Stock3,Xlab = "Date", ylab = "Stock3", main = "Time Series Plot of Stock3")
par(mfrow=c(3,3))#log returns for Stock1
log_returns1 <- diff(log(Stock1), lag=1)
#log_returns in percentages
p <- c()
for(i in log_returns1){
p <- (log_returns1[i]/sum(log_returns1))*100
print(p)
}
summary(log_returns1)
N <- length(log_returns1)
k <- mean(log_returns1)
StandardDeviation<- sqrt(var(log_returns1))
m1=sum(log_returns1 - k)/N
m2=sum((log_returns1 - k)^2)/N
m3=sum((log_returns1 - k)^3)/N
m4=sum((log_returns1 - k)^4)/N
Sk<- m3/StandardDeviation^3;Sk
Kurtosis <- m4/(m2)^2;Kurtosis
#log returns for Stock2
log_returns2 <- diff(log(Stock2), lag=1)
#log_returns in percentages
p <- c()
for(i in log_returns2){
p <- (log_returns2[i]/sum(log_returns2))*100
print(p)
}
summary(log_returns2)
N <- length(log_returns2)
k <- mean(log_returns2)
StandardDeviation<- sqrt(var(log_returns2))
m1=sum(log_returns2 - k)/Nm2=sum((log_returns2 - k)^2)/N
m3=sum((log_returns2 - k)^3)/N
m4=sum((log_returns2 - k)^4)/N
Sk<- m3/StandardDeviation^3;Sk
Kurtosis <- m4/(m2)^2;Kurtosis
#log returns for Stock3
log_returns3 <- diff(log(Stock3), lag=1)
#log_returns in percentages
p <- c()
for(i in log_returns3){
p <- (log_returns3[i]/sum(log_returns3))*100
print(p)
}
summary(log_returns3)
N <- length(log_returns3)
k <- mean(log_returns3)
StandardDeviation<- sqrt(var(log_returns3))
m1=sum(log_returns3 - k)/N
m2=sum((log_returns3 - k)^2)/N
m3=sum((log_returns3 - k)^3)/N
m4=sum((log_returns3 - k)^4)/N
Sk<- m3/StandardDeviation^3;Sk
Kurtosis <- m4/(m2)^2;Kurtosis
#Correlation Matrix of 3 Stocks
y <- data.frame(log_returns1,log_returns2,log_returns3)
cor(y)
#(d)
data1 <- read.csv("C:\\Users\\Ahmad\\Downloads\\FF3factors.csv", header= TRUE)
Mkt.RF<- data1$Mkt.RF
SMB <- data1$SMB
HML <- data1$HML
RF <- data1$RF;length(RF)
data <- read.csv("C:\\Users\\Ahmad\\Downloads\\Stock.csv", header= TRUE)
Stock1 <- data$MSFT
log_returns1 <- diff(log(Stock1), lag=1)
m1 <- log_returns1-RF;m1
Stock.Rf1 <- m1-RF
fit <- lm(Stock.Rf1~Mkt.RF);fit
Stock2 <- data$MMM
log_returns2 <- diff(log(Stock2), lag=1)
m2 <- log_returns2-RF;m2
Stock.Rf2 <- m2-RF
fit1 <- lm(Stock.Rf2~Mkt.RF);fit1
Stock3 <- data$INTC
log_returns3 <- diff(log(Stock3), lag=1)
m3 <- log_returns3-RF;m3
Stock.Rf3 <- m3-RF
fit2 <- lm(Stock.Rf3~Mkt.RF);fit2
#(e)
fit3 <- lm(Stock.Rf1~Mkt.RF+SMB+HML);fit3
fit4 <- lm(Stock.Rf2~Mkt.RF+SMB+HML);fit4
fit5 <- lm(Stock.Rf3~Mkt.RF+SMB+HML);fit5
#(h)
SharpeRatio1 <- (0.05-0.02)/24.65827;SharpeRatio1
SharpeRatio2 <- (0.05-0.02)/45.25654;SharpeRatio2
SharpeRatio3 <- (0.05-0.02)/9.488162;SharpeRatio3
#(j)
data <- read.csv("C:\\Users\\Ahmad\\Downloads\\Stock.csv", header= TRUE)
Stock1 <- data$MSFT
Stock2 <- data$MMM
Stock3 <- data$INTC
Date <- data$Date
returns <- getReturns(names(stocks[-1]), freq="week")
eff.frontier<- function (returns, short="no", max.allocation=NULL,
risk.premium.up=.5, risk.increment=.005){
covariance <- cov(returns)
print(covariance)
n <- ncol(covariance)
Amat<- matrix (1, nrow=n)
bvec<- 1
meq<- 1
# Then modify the Amat and bvec if short-selling is prohibited
if(short=="no"){
Amat<- cbind(1, diag(n))
bvec<- c(bvec, rep(0, n))
}
if(!is.null(max.allocation)){
if(max.allocation> 1 | max.allocation<0){
stop("max.allocation must be greater than 0 and less than 1")
}
if(max.allocation * n < 1){
stop("Need to set max.allocation higher; not enough assets to add to 1")
}
Amat<- cbind(Amat, -diag(n))
bvec<- c(bvec, rep(-max.allocation, n))
}
# Calculate the number of loops
loops <- risk.premium.up / risk.increment + 1
loop <- 1
eff <- matrix(nrow=loops, ncol=n+3)
# Now I need to give the matrix column names
colnames(eff) <- c(colnames(returns), "Std.Dev", "Exp.Return", "sharpe")
# Loop through the quadratic program solver
for (i in seq(from=0, to=risk.premium.up, by=risk.increment)){
dvec<- colMeans(returns) * i # This moves the solution along the EF
sol <- solve.QP(covariance, dvec=dvec, Amat=Amat, bvec=bvec, meq=meq)
eff[loop,"Std.Dev"] <- sqrt(sum(sol$solution*colSums((covariance*sol$solution))))
eff[loop,"Exp.Return"] <- as.numeric(sol$solution %*% colMeans(returns))
eff[loop,"sharpe"] <- eff[loop,"Exp.Return"] / eff[loop,"Std.Dev"]
eff[loop,1:n] <- sol$solution
loop <- loop+1
}
return(as.data.frame(eff))
}
# Run the eff.frontier function based on no short and 50% alloc. restrictions
eff <- eff.frontier(returns=returns$R, short="no", max.allocation=.50,
risk.premium.up=1, risk.increment=.001)
#Task2
data2 <- read.csv("C:\\Users\\Ahmad\\Downloads\\Event Study.csv", header= TRUE)
y <- data2$Return
x1 <- data2$total.change
x2 <- data2$surprise
x3 <- data2$expected
x4 <- data2$Scheduled
fit1 <- lm(y~x1)
summary(fit1)
fit2 <- lm(y~x3)
summary(fit2)
fit3 <- lm(y~x2)
summary(fit3)
#c
z <- x4*x3
fit4 <- lm(y~z)
summary(fit4)
References:
- Matloff, S.N. (2011). The Art of R Programming. No Starch Press.
- Crawley, Michael J. (2013). The R book. Data analysis assignment Chichester, West Sussex, United Kingdom :Wiley,