Business Intelligence Assignment: Role of Big Data in Healthcare Industry
Question
Task
In this business intelligence assignment, you are required to produce a report based on the Big Data strategy. You also need to analyse the datasets relevant to the business using any big data tools and describe how the outputs of these tools could help you to create the Big Data Strategy. You can include any additional datasets that would support your big data strategy.
At the beginning of the report, you will identify some Big Data use cases based on the Big Data strategies. In the following part, you will critically analyse different Big Data technologies, data models, processing architectures and query languages and discuss the strengths and limitations of each of them.
You will also discuss different Big Data analytics and business intelligence tools that can be applied on the chosen datasets so businesses can gain actionable insights from Big Data. Moreover, you will discuss the Big Data technologies that you could use for data collection, storage, transformation, processing and analysis to support your use cases.
You will also illustrate the Big Data technology stack and processing architecture required to support your use cases. You have to provide the rationale behind each of the choices you make. Finally, you will specify what user experiences you are going to provide to aid in decision-making. Your target audience is executive business people who have extensive business experience but limited ICT knowledge. Hence, they would like to be informed as to how new Big Data technologies that you have applied on the datasets could benefit their business. Please note that a standard report structure, including an executive summary, must be adhered to.
The main body of the report should include but not limited to the following topics:
1. Big Data Use Cases
2. Critical Analysis of Big Data Technologies
3. Big Data Architecture Solution
The length of the report should be around 3000 words. You are required to do an extensive reading of more than 10 articles relevant to the chosen Big Data use cases, technologies, architectures and data models
Answer
Executive Summary
It is evident in this business intelligence assignment that big data analytics has provided cancer researchers a powerful way to utilize data for the benefit of humankind. There is immense potential in the field of healthcare otherwise as well, with big data helping in identification of trends, enabling preventive care, assisted living, providing a holistic view of healthcare and aiding in cost reductions.
For healthcare providers, the utilization of big data extends to creating a sustainable competitive advantage lying either on the side of cost leadership or differentiation. Thus, it has become an imperative for healthcare providers to consider applications of big data to clearly defined business goals.
A critical analysis of various big data technologies has been carried out for data storage, mining and visualization. Data storage is commonly on Hadoop environment, where the other available option is MongoDB. However, Hadoop is preferred if data sets are larger and complex. This applies to the healthcare industry where patient’s electronic health care record needs to be combined with other data sources like wearables, genomic data etc. Further, for data mining or analytics, there are several options like RapidMiner, Elasticsearch, Spark, R language which can be explored. Tableau has established its worth as a powerful visualization tool that is growing in popularity. The basic big data architecture that has been identified for healthcare provider has following components – a) Hadoop environment with HDFS, Hive, Hue, Spark for data storage and processing, and, b) Tableau for data visualization.
Breast cancer dataset has been analysed using the R language to build a classification model. The applicable use case is identification of patient’s mass as malignant or benign based on her diagnostic results. This exercise aims at making diagnosis possible at an earlier stage of cancer, so that, chance of survival is higher and quality of life is improved. This provides a great advantage to healthcare provider’s differentiation strategy, as it can claim to be a patient-centric organization by building on similar initiatives.
Introduction
Big data is a cutting-edge technology that has enabled humans to personalize and customize products and services to their own likes. It has ensured that we are no longer impacted by general market trends and decisions based on aggregate data. The three most important aspects of big data are – volume, velocity and veracity (Laney, 2001) have enabled several organizations to thrive. Several organizations have used analytics and business intelligence to create a core technology differentiated offering. Some of them have used big data insights to establish a cost leadership (The value of Big Data: How analytics differentiates winners, 2020) and improve their services.
Healthcare industry stands to benefit a lot from big data applications. An organization should try to create a sustainable competitive advantage. To achieve this, it should strive to either be a cost leader or have a differentiated product or service offering. Some examples of how players in the healthcare sector can benefit are –
- Cost leadership: pharmaceutical companies are striving hard to develop new drugs and treatments with minimum expense. Research & development usually contributes to the biggest chunk of cost. Companies have been able to reduce costs by more than 10% (Big data analysis shown to increase revenues and reduce costs - BARC - Business Application Research Center, 2020)
- Differentiation: healthcare providers have a lot of data that can be used to personalize services for the patients. There are many takers of such customized services at a premium price (Panner, 2020). Healthcare providers should take this up as an opportunity to become patient-centric.
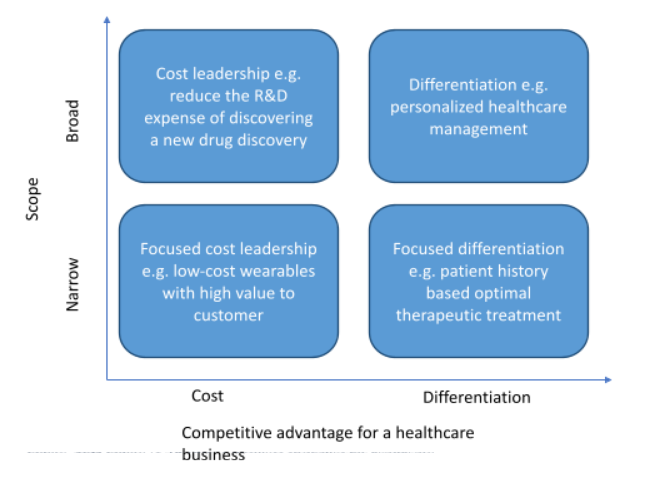
Organizations can define their business strategies around utilizing their big data capabilities. It can become a source of competitive advantage for the organization if executed well.
Big Data Use Cases
Healthcare industry has been chosen to elaborate on the various use cases of big data. It is one of the industries where big data can not only help businesses survive and thrive, but also improve the quality and longevity of human life in general.
a. Identify health trends and provide preventive care
Traditional data systems are not able to handle the increasing amount of patient data and have been replaced by big data everywhere. Electronic healthcare records are being used to evaluate diseases and in epidemiology(Chen, Lin and Wu, 2020). Martin-Sanchez and Verspoor (2014) have identified that healthcare providers are creating information assets. With the help of big data, medical community has been able to identify emerging trends and provide preventive care.
b. Holistic understanding of patient health
Business intelligence on patient records, medical history, insurance data etc. can provide the practitioners with a holistic view of patient health. This can be used to administer better treatment pathways and drug combinations.
c. New drug discovery and personalized healthcare
According to Costa (2014), molecular data has been analysed to identify new drugs and treatments which are more effective. A combination of genome and diagnostic data is being used to personalize healthcare for individuals based on their genetic makeup.
d. Reducing cost of healthcare
A patient can be prescribed a number of therapies based on the disease they are suffering from. Practitioners are used to their own experience with the therapies to determine the ideal path for the patient. However, it has been identified that the outcome of two or more therapies can be same for patients. But, one of these therapies may be less expensive than the other. Big data analytics can help select the optimal therapy for the patients (Rai and Goyal, 2018).
e. Early diagnosis of diseases and improved quality of care
Distributed healthcare application is a possibility due to Internet of Things (IoT). Progress in this technology has led to improvement in tracking of physiological parameters. Early diagnosis of disease, care of chronic diseases and better response to emergencies has become a possibility (Aceto, Persico and Pescapé, 2020).
f. Assisted living
While medical advancements have prolonged life of individuals, it has caused the rise in need for assisted living. Elderly can be monitored with the help of different devices, and the data can be centrally analysed for abnormalities. This is sensor data from wearables e.g. blood pressure, sugar levels, ambient information, heart rate (Aceto, Persico and Pescapé, 2020). Remote monitoring has given a different meaning to assisted living wherein clinical interventions can be made as required.
g. Rehabilitation
With the help of wearable technology, home-bound rehabilitation can also help reduce the expenditure on healthcare. It also leads to better quality care and environment for the patient. There is need for real-time tracking of human movements and alerting a central system in case required. A customized solution can help the patient self-monitor and improve health.
Use of Big Data tools on the dataset
The chosen dataset has been picked from UC Irvine Machine Learning repository. The breast cancer diagnostic data (Index of /ml/machine-learning-databases/breast-cancer-wisconsin, 2020) chosen here is sample data with 699 records and 10attributes. All data analytics has been performed using R language.
Use case: identify if patient’s mass is benign or malignant based on diagnostic results
a. Data pre-processing
One of the important aspects of business intelligence is availability of clean data. For this, data preprocessing is required where outliers are removed and missing data is imputed. In the current dataset, missing values have been replaced with the mean value of the attributes.
b. Data description
The data contains a sample code number which can be ignored for the analysis. Of the other attributes, the class attribute is the outcome field which can be split into benign and malignant records. Other attributes are predictors on the basis of which the outcome is to be determined.
|
Attribute |
Type |
|
Sample code |
Random number |
|
Thickness – Clump |
1-10 |
|
Cell size uniformity |
|
|
Cell shape uniformity |
|
|
Adhesion |
|
|
Epithelial cell size |
|
|
Nuclei |
|
|
Chromatin |
|
|
Nucleoli |
|
|
Mitoses |
|
|
Benign vs. Malignant |
2 or 4 |
Table 1 Data description of chosen dataset
c. Feature selection
With the help of OneR library, the breast cancer data has been modelled to identify the accuracy of predictors in estimating class of mass.
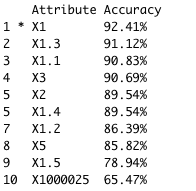
Figure 2 Feature selection
This indicates that that the top attributes for prediction of class are – uniformity of cell size and shape. These are the dominant features with a cut off accuracy of 91% in the dataset.
d. Classification of dataset
Based on the features selected above, the dataset has been classified to identify the accuracy of these predictors for class identification.
A summary of the model yields following output –

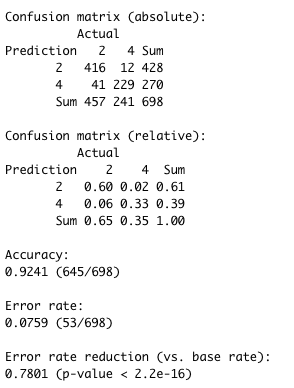
The model can correctly predict breast cancer with an accuracy of 92.41%. p-value of the Chi-square test is <0.05, thus, the confidence level for the prediction is more than 95%.
Critical analysis on the output
The results of analytics on the breast cancer data can be further improved by using different classification models which are more accurate. One such algorithm is the K-nearest neighbour model, which is simple and effective. The nearest distance samples from training data are classified together. It is widely used in biomedical research and applications.
Based on the current method, the output accuracy is 92.41%, which can be considered as low for a use-case with such great implications. Only two attributes have been considered as predictors, while there could be other attributes which when transformed become relevant. Improved feature selection can also help increase model accuracy. Diagnosis should be accurate and healthcare providers should strive to be right at first.
User experience
Users of this dataset are typically the practitioners employed with the healthcare organization. The envisioned user experience involves providing them with a comprehensive customer details tool with below components –
- Patient history – past patient interactions, records of diseases suffered and treatments administered
- Patient diagnostics – the results of patient’s diagnostic tests
- Patient vitals – an integration with wearables can be done for real-time updates on patient’s vitals
Business benefit
A healthcare organization can utilize this use-case for following business benefits (Richard Kimball, 2020)
- Business mission re-defined: to become a patient-centric organization
- Increase in number of customers: improve patient / customer pull towards the healthcare provider by depicting themselves as a cutting-edge healthcare technology company
- Increase patient loyalty: with advanced offerings that includes proactive risk determination w.r.t to patients health and personalized care, healthcare providers can win patient loyalty
- Improve patient engagement: with post-recovery services and regular tracking of patient’s diagnostic results, healthcare providers can prompt patients to make lifestyle updates and keep them engaged
Critical Analysis of Big Data Technologies
There are three types of big data technologies prevalent in the industry, based on business needs. Technologies for storing data, for mining data and for reporting or visualization.
a. Big data technologies for data storage
The most common technologies(Dede et al., 2013) used for data storage are HDFS and MongoDB
- MongoDB: it is NoSQL based and uses a ‘document store’ structure. Strengths -
- Data is not storedin rows and columns, but stored in documents. It uses a ‘sharding’ to split the data into different clusters for parallel processing. The entire server on which the data is hosted is broken into a set of front-end and back-end servers
- MongoDB works well in optimizing existing DBMS
- Database is de-normalized which impacts space optimization. It impacts the read and write operation and makes it more expensive
- Hadoop/HDFS (Hadoop distributed file system) Strengths –
- It stores and processes data in a distributed environment to enable parallel processing
- The YARN or yet another resource negotiator works in Hadoop environment to allocate resources
- Hadoop is easily scalable and fault tolerant
- Hadoop is suitable for large datasets and MongoDB works better for smaller datasets
- As data is stored in external nodes, there are security concerns within the Hadoop environment
Weaknesses –
Weaknesses –
b. Big data technologies for data mining
The top data mining technologies are Elasticsearch and RapidMiner. These are the most popular tools used by most businesses
- RapidMiner
- Biggest advantage of RapidMiner over other data mining technologies is its user interface which is highly intuitive
- In RapidMiner, users can create advanced workflows, automate using scripts in multiple languages (Hirudkar and Sherekar, 2013)
- There are limited modules in RapidMiner which restricts data analytics capabilities
- The interface is not coder-friendly which makes it difficult to use by developers, this also limits its flexibility
- Elasticsearch: is open-source technology Strengths –
- It is more like a search engine. It is used for querying and monitoring in documents
- It is however more versatile than traditional databases. It can execute complex queries
- It is horizontally scalable
- RapidMiner is preferred over Elasticsearch if the data volume is very large
- Elasticsearch doesn’t support database transactions, joins
Strengths –
Weaknesses –
Weaknesses -
c. Big data technologies for visualization
The most widely preferred visualization tools are Tableau and Microstrategy -
Tableau: Business intelligence industry has very well adapted Tableau
Strengths –
- Easy to use interface and powerful visualization options
- It is intuitive and easily customizable as per needs
- Tableau licenses are low-cost and they provide good support
Weaknesses –
- There is no versioning inbuilt in Tableau, which makes version control difficult
- It is not considered to be a comprehensive reporting solution
Micro strategy: it is a powerful reporting tool Strengths –
- It is easy to use for developers who have expertise with coding
- There are a number of out of the box features that make report development faster
Weaknesses –
- It requires a level of expertise to master this tool
- There have been reported issues with unstructured dataset handling
Big Data Technology Stack and Processing Architecture
Big data architecture should be carefully defined by the organization, based on its needs and business goals. It is a huge investment and the switching costs are usually high. The recommended big data architecture for healthcare providers is depicted in figure 4. Various components are –
Choice of database – Hadoop vs. MongoDB
Recommended database is Hadoop due to the following rationale -
- Healthcare data contains patient electronic health records, genetic, diagnostic, wearable data etc. Such large datasets can be handled in Hadoop better than MongoDB
- Another advantage of Hadoop system over MongoDB is that it provides greater space optimization and utilization. Its read and write performance is also better, while similar tasks are more expensive in MongoDB
About the Hadoop environment
Hadoop environment is where all the data is stored and handled. This environment is preferred for big data analytics as it is reliable. Workload is divided into multiple nodes.Also, it is less expensive than the traditional systems with additional benefit of volume and velocity. Hadoop is an open-source platform and has three important characteristics – it is distributed, scalable and is fault tolerant. Hadoop environment has been very well adopted in the industry mostly because of a number of advantages like ability to process complex data and economical scalability.
There are several components of the Hadoop environment which have to be assembled for big data analytics, as it is a plug and play architecture. There are a number of Hadoop distributions available in the market. Organizations can choose basis their requirement and budget constraints. Apache Hadoop which is also called vanilla flavoured distribution is the least expensive of all. For quality data analytics due to the available technical support, Cloudera distribution is highly recommended, however it falls on the expensive side.
- HDFS: it is a self-healing. Data is stored in clustered. This system enables storing both structured and unstructured data. HDFS is not bound by a single schema, and can mine any type of data. In case of node failure, there is a backup node with duplicate data that can replace the faulty node and not impact analysis.
- Hive: it is the data warehousing layer on top of the HDFS. It allows analysis through SQL like queries and is best for those who are familiar with this language.
- Query languages: there are multiple query languages that can be used to extract information from Hive database. Some of the popular languages are Impala and Spark. A quick comparison here can help business decide the language it should go with based on its needs –
Table 2 Big data query languages
|
Impala |
Spark |
|
|
- Hue: it is the web interface that makes data processing very intuitive in the Hadoop environment. Users can view the metadata, database tables, execute queries, check performance etc.
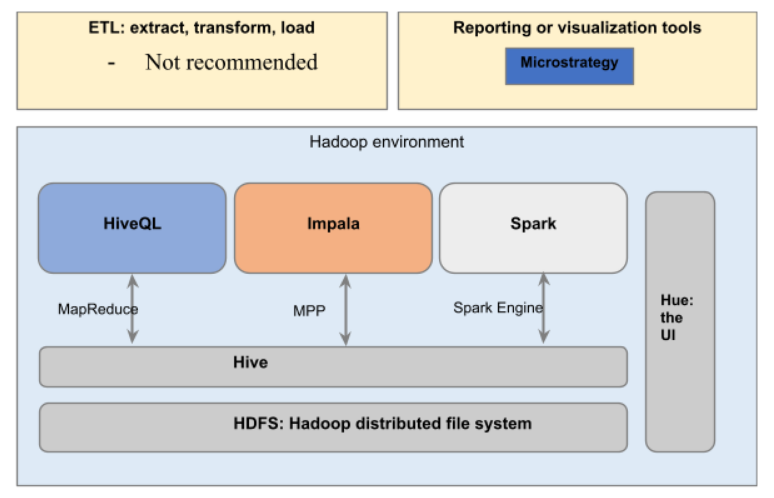
Distributed File System
Distributed Database
Execution Engines
Query Language
Web interface to view DB tables, HDFS files, Execute queries etc.
External Tools
Choice between ETL tools –
Apart from the data storage and processing layer. There are external connectors to the Hadoop environment that make big data analytics possible. These include ETL tools like Alteryx, SnapLogic and Informatica – big data management. These tools allow users to define workflows for data processing and simplify the entire data management.
For the purpose of the use-case, such an ETL tool is not required and is not recommended.
R programming language is recommended for the use-case in consideration. It is a reliable tool with capability to derive statistical interpretations from big data sets. It makes plotting easy and is independent of platform.
Choice of visualization tools – Tableau vs. MicroStrategy
Recommended tool is MicroStrategy based on following rationale for healthcare business -
- It is more scalable and is better at handling larger data sets. This makes it better suited tool for healthcare
- It also has in-built data wrangling feature and can blend in data from multiple sources
The use-case in consideration is a statistical in nature with binary outcome, and doesn’t require a visualization tool for insights.
Conclusion
It has been established that big data analytics can help a business identify itself as a cost-leader or differentiator. Healthcare providers can enhance various activities part of the primary and secondary value chain to achieve this. Further, the explored use case of identifying breast cancer in patients is one of the examples of how healthcare providers can lead with their differentiation strategy. A range of similar big data use cases can help them identify as patient-centric business, working for the welfare of people. Such applications not only help patients lead a better-quality life but also saves them from the emotional stress of realizing that they are suffering from a terminal disease at a late stage.
Appendix
R code:
mydata<-read.csv(file.choose())
head(mydata)
install.packages("OneR")
library(OneR)
mydata<- optbin(mydata, method = "infogain")
predmodel<- OneR(mydata, verbose = TRUE)
summary(premodel)
plot(premodel)
classpredict<- predict(premodel, mydata)
eval_model(classpredict, mydata)
Model evaluation:
References
[1] Aceto, G., Persico, V. and Pescapé, A., 2020. Industry 4.0 and Health: Internet of Things, Big Data, and Cloud Computing for Healthcare 4.0. Journal of Industrial Information Integration, 18, p.100129.
[2] Bain. 2020. The Value Of Big Data: How Analytics Differentiates Winners. [online] Available at:
[3] BARC - Business Application Research Center. 2020. Big Data Analysis Shown To Increase Revenues And Reduce Costs - BARC - Business Application Research Center. [online] Available at:
[4] Chen, P., Lin, C. and Wu, W., 2020. Big data management in healthcare: Adoption challenges and implications. International Journal of Information Management, p.102078.
[5] Costa, F., 2014. Big data in biomedicine. Business intelligence assignment Drug Discovery Today, 19(4), pp.433-440.
[6] Dede, E., Govindaraju, M., Gunter, D., Canon, R. and Ramakrishnan, L., 2013. Performance Evaluation Of A Mongodb And Hadoop Platform For Scientific Data Analysis. [online] Datasys.cs.iit.edu. Available at:
[7] Laney, D 2001, ‘3D Data Management: Controlling Data Volume, Velocity, and Variety’, Gartner File No. 949, viewed 22 April 2020,
[8] Panner, M., 2020. Council Post: Personalized Medicine: The Trend That's Sweeping Health Care. [online] Forbes. Available at:
[9] Rai, M. and Goyal, R., 2018. Pharmacoeconomics in Healthcare. Pharmaceutical Medicine and Translational Clinical Research, pp.465-472.
[10] Richard Kimball, F., 2020. 5 Ways Your Hospital Can Benefit From Patient-Centered Care: The Patient-Centered Care Model Is Here To Stay. More Than A Trend, Industry Experts And Policy Advocates Everywhere Have Touted It As The Strategy That Will Fix The Healthcare System Once And For All.. [online] Beckershospitalreview.com. Available at:
[11] Verspoor, K. and Martin-Sanchez, F., 2020. Big Data In Medicine Is Driving Big Changes.
[12] Archive.ics.uci.edu. 2020. Index Of /Ml/Machine-Learning-Databases/Breast-Cancer-Wisconsin. [online] Available at: